Big Data Analysis with R
When the database grows in size, it is important to find the solution that best suits your needs. In this course we start with the use of databases to analyze a much larger data than the one that’s accessible with the simple R and we will move on increasing the data size until we understand how the distributed architectures work and how to use Apache Hadoop and Apache Spark with R and Sparklyr.
Topics include
- Introduction to data lakes
- The fundamentals of database theory
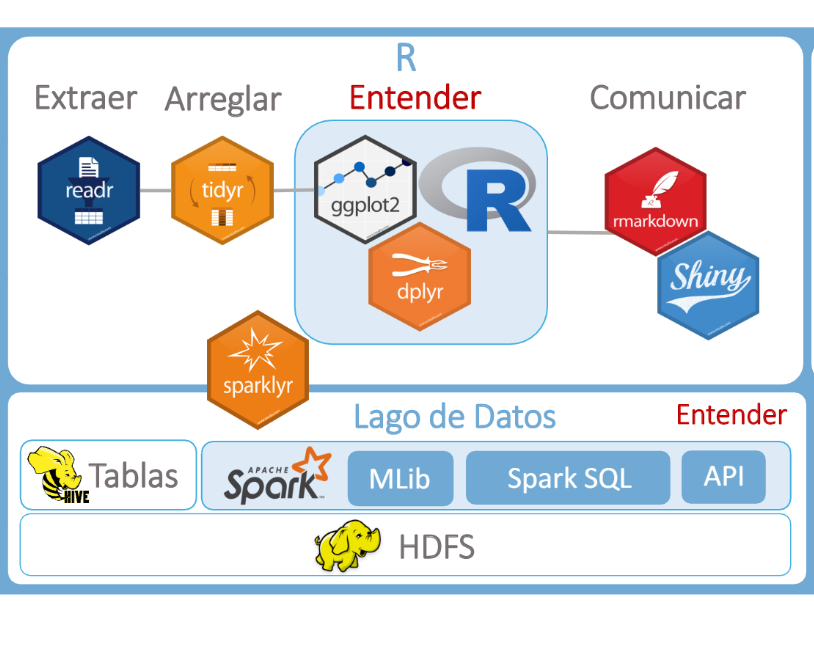
- Main technologies for data lakes
- Manipulate data on the disk
- Lazy operations
- Data Import and Manipulation
- Distributed Architectures
- Principles
- Cloudera HDFS
- Hive and Apache Spark
- Sparklyr
- Standalone testing mode and distributed mode
- Data Import and Distributed Manipulation
- Relational data and Joins
- In-memory Caching
- In-memory Distributed computation
- Machine Learning Pipelines
- Introduction to the main Machine Learning Algorithms
What you will be able to do
- Select the architecture that best suits your needs, selecting which type of database or distributed architecture.
- Import, manipulate data in that architecture
- Understand the basics and the limitations of the architecture in terms of data and of kind of analysis
- Use the main Machine Learnings algorithms on a distributed architecture
Duration
2 days.
Pre requisites
- Basics of R programming and Tidyverse
- Nice to have: Dplyr or SQL basics
Audience
This course provides the foundations for analyzing and using a big dataset and is also recommended for anyone who needs to understand how the size of the data affects the analysis process or results and, consequently, understand what benefits the usage of these technologies provides to the business.